이번 글은 Toss Tech에 작성된 "서버 증설 없이 처리하는 대규모 트래픽"을 정리했습니다.
출처 : https://toss.tech/article/monitoring-traffic
서버 증설 없이 처리하는 대규모 트래픽
늘어나는 트래픽을 잘 처리하기 위해 서버 개발자는 어떤 고민을 해야 할까요? “라이브 쇼핑 보기” 서비스에 대규모 트래픽이 들어오면서 겪은 문제와 해결책을 공유드려요.
toss.tech
라이브 쇼핑 보기 서비스 론칭 당시 예상보다 많은 유저가 몰렸고, 이후에도 신규 유저와 광고주가 꾸준히 늘어나며 서비스가 빠르게 성장함으로 인해 발생하는 문제의 해결 방법을 다룹니다.
급격하게 성장하는 서비스가 겪는 문제
라이브 쇼핑보기 서비스는 초당 수십만 건의 요청이 발생하는 급격히 성장하는 서비스로, 트래픽 증가가 서버에 심각한 부담을 줄 수 있습니다. 트래픽이 급장하면 쓰레드 지연, 데이터베이스·캐시·게이트웨이 등에서 장애가 발생할 수 있고, 캐시 누락은 DB에 과부하를 줄 수 있습니다. 서버 증설은 한 가지 해결책이지만, 비용 문제와 자원 낭비, 그리고 증설만으로 해결되지 않은 문제들도 존재합니다.
라이브 쇼핑 서버가 만났던 문제
라이브 쇼핑 서버는 유저 수 증가로 Redis에 저장하고 조회하는 데이터량과 커맨드 수가 급격히 늘어나면서 Redis 과부하 문제가 발생합니다. Redis 과부하는 결국 데이터베이스 부하로 이어질 수 있기 때문에 심각한 문제입니다.
Redis에서 캐싱하는 데이터는 모든 유저가 공유하는 Universal Data와 유저별로 사용하는 User-Specific Data로 나뉩니다. Universal Data는 Redis에 읽기 요청이 집중되어 CPU와 네트워크에 부담을 주는데, 이를 해결하기 위해 웹 서버의 Local Cache를 사용해 Redis 의존도를 낮추고, Redis의 Pub/Sub 기능을 통해 로컬 캐시를 빠르게 초기화하는 방법을 사용할 수 있습니다.
User-Specific Data는 유저 수 증가에 따라 캐시 데이터 양과 메모리 사용량이 함께 증가하는데, 다양한 압축 기법을 적용해 데이터 크기를 줄이면 메모리 사용량을 줄일 수 있습니다. 다만, 너무 작은 데이터를 압축하면 오히려 데이터 크기가 증가할 수 있으므로 주의가 필요합니다.
또한 Redis가 장애로 인해 작동하지 않을 경우를 대비해, 데이터베이스에 직접 부하가 가지 않도록 Fallback 로직을 마련하는 것이 중요합니다.
커맨드 수
Redis에게 보내는 명령어(예: 데이터 저장, 조회 요청)의 수
Universal Data (범용 데이터)
든 사용자에게 똑같이 보여지는 데이터
예: 쇼핑 방송 목록, 상품 정보 등
User-Specific Data (개별 사용자 데이터)
각 사용자마다 다른 데이터
예: 내가 어떤 방송을 봤는지, 어떤 상품을 찜했는지 등
Local Cache (로컬 캐시)
서버 안에 있는 작은 저장 공간
Redis까지 가지 않고, 서버 내부에서 바로 데이터 가져와 더 빠르게 처리 가능
Redis Pub/Sub
Redis의 발행-구독 기능.
어떤 서버가 “데이터 바뀌었어!” 하고 외치면, 구독 중인 서버들이 그걸 듣고 자신의 데이터를 갱신
→ 여러 서버의 캐시를 자동으로 동기화할 때 사용
Fallback 로직
문제가 생겼을 때 대신 작동하는 예비 로직.
예: Redis가 고장 나면, 직접 DB에 접근하지 않도록 우회 경로를 설정하는 방식.
선착순 포인트 지급과 데이터베이스 과부하 문제
라이브 쇼핑 서비스가 커지면서 포인트 지급 요청이 몰려드는 일이 많아졌고, 이를 잘 처리하지 않으면 문제들이 생길 수 있었다.
예를 들어, 같은 유저에게 포인트가 두 번 지급되거나, 포인트가 지급되었는지 바로 알 수 없거나, 데이터베이스가 너무 많은 요청을 받아서 느려지거나 멈출 수 있었습니다.
그래서 해결 방법으로는, 먼저 중복 지급을 막기 위해 한 유저에 대해 동시에 여러 요청이 들어오지 못하게 RedLock이라는 기술로 잠금을 걸었습니다.(멀티 노드 환경)
그리고 유저가 포인트를 받았는지 바로 알 수 있도록 먼저 Redis에 포인트 지급 내역을 저장해서 빠르게 응답했습니다.
마지막으로, 데이터베이스에 부담을 주지 않기 위해 Kafka를 사용해 포인트 지급 내역을 나중에 천천히 저장하도록 처리했고, 동시에 너무 많은 데이터가 몰리지 않게 속도 제한(Throttling)도 걸었습니다.
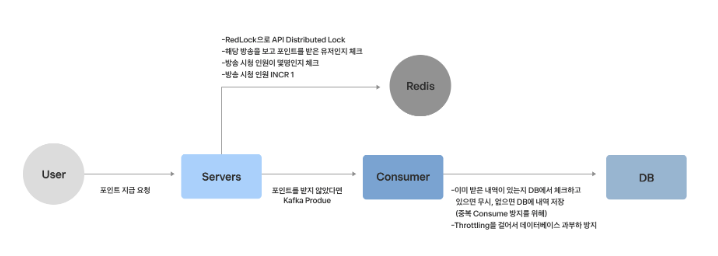
선착순 포인트 지급에서는 “지정된 수만큼만 포인트를 주는 것”이 중요한데, 이걸 위해 Redis의 Increment 기능을 사용합니다. 예를 들어, 포인트 지급 수를 100명으로 정했다면, 지급할 때마다 1씩 더해서 100명이 되면 지급을 멈추는 방식입니다.
Redis는 한 번에 하나씩 처리하는 구조(Single-Thread)이기 때문에 Increment는 안전하게 처리되지만, 너무 많은 요청이 동시에 들어오면 Redis가 처리하느라 느려지고 CPU가 높아지는 문제가 생깁니다.

이 문제를 줄이기 위해, 서버에서 미리 유저 수를 세다가, 일정 시간마다 한 번에 Redis에 반영(Flush)하는 방법을 쓸 수 있습니다. 다만 이 방법은 정확히 순서를 보장하지 않기 때문에, 진짜 선착순이 중요한 서비스라면 적합한지 잘 따져봐야 합니다.
Redis의 INCR(increment)는 atomic하게 동작하므로, 동시성을 제어 해줍니다.
즉, 여러 클라이언트가 동시에 같은 키에 INCR 요청을 보내도, Redis는 이를 하나씩 순차적으로 처리하기 때문에
중간에 값이 꼬이거나 덮어씌워지는 일이 없습니다.
API 중복 요청 및 Gateway 과부하 문제
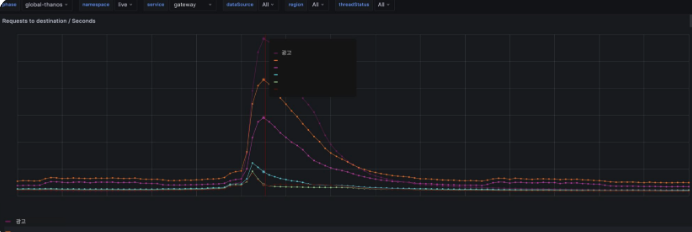
라이브 쇼핑 서비스는 피크 시간대에 너무 많은 트래픽이 몰리면서, 이를 줄이기 위해 중복 요청 제거와 API 통합 방법을 적용했습니다.
중복 요청은 한 유저가 짧은 시간에 같은 API를 여러 번 호출하는 현상으로, 서버에 불필요한 부하를 주게 됩니다. 이런 중복 요청이 많아질수록 Gateway, 웹서버, Redis, 데이터베이스 등 전체 시스템이 부담을 받게 되고, 특히 요청과 응답을 모두 암호화해야 하는 Gateway에는 큰 영향을 줄 수 있습니다.
이 문제를 해결하기 위해, 트래픽이 많은 유저를 기준으로 로그를 분석해 어떤 상황에서 중복 요청이 발생하는지 확인했습니다. 확인된 중복 요청은 클라이언트 개발자와 협업해 제거하고, 서비스에 문제가 없는지도 함께 확인했습니다.
또한 라이브 쇼핑에 접속할 때 한 번에 세 개의 API가 동시에 호출되도록 되어 있었는데, 이를 하나의 API로 합쳐서 /view라는 하나의 API에서 모든 정보를 응답하도록 변경했습니다. 이렇게 통합한 결과 피크 트래픽이 절반으로 줄었습니다. 다만, 응답 시간이 긴 API는 하나로 묶으면 전체 응답이 느려지기 때문에 상황에 따라 통합하거나 분리하는 것이 필요합니다.
맺음말
서비스가 빠르게 성장하면 예상하지 못한 성능 문제가 계속 생길 수 있습니다. 이런 문제를 막기 위해서는 성능 개선 작업을 한 번 하고 끝내는 것이 아니라, 지속적으로 반복하는 과정, 즉 성능 개선의 이터레이션이 필요합니다.
이 이터레이션은 다음과 같은 순서로 반복됩니다.
1. 서버를 모니터링해서 문제를 발견하고
2. 어떤 문제가 있는지 원인을 파악한 후
3. 해결책을 찾아 적용하고
4. 카나리 배포(일부 사용자에게만 먼저 적용)를 통해 이상이 없는지 다시 모니터링합니다.
카나리 배포란?
카나리 배포(Canary Deployment)는 새로운 버전의 코드를 전체 사용자에게 한꺼번에 적용하지 않고, 일부 사용자에게 먼저 적용해보는 배포 방식입니다.
이 과정을 반복하면 서버 증설 전에 성능 문제를 개선할 수 있는 기회를 얻을 수 있고, 불필요한 리소스 낭비도 줄일 수 있습니다.
또한 프로파일러를 사용해 연산이 많거나 메모리를 많이 쓰는 부분을 찾아 최적화해야 하고, 중복된 로직이 없는지도 점검해서 제거해야 합니다. 최적화한 버전은 카나리 배포로 점진적으로 적용하면서 성능이 정말 나아졌는지도 확인해야 합니다.
무엇보다 중요한 것은 모니터링 환경을 잘 갖추는 것입니다. 서버뿐 아니라 Redis, DB, Kafka 같은 연결된 시스템과 PV, UV, 리텐션 같은 서비스 지표를 실시간으로 확인하고, 문제가 생기기 전에 미리 경고(Alert)를 받을 수 있도록 해야 합니다.
결국, 모니터링이 성능 개선의 출발점이자 끝입니다.
이런 반복적인 개선 과정을 통해 서비스가 급성장해도 안정적으로 운영할 수 있습니다.
배운점
- 유저 수와 요청이 늘어나면 서버, DB, Redis 등에 부하가 걸려 장애 발생 가능
- 단순 서버 증설은 한계가 있고, 비용도 큼
- Redis 과부하를 줄이기 위해 Local Cache도 활용 가능
- Kafka를 활용한 비동기 처리로 DB 데이터 저장으로 발생하는 부하 감소
- 중복 API 요청으로 트래픽이 증가할 시, 하나의 API로 통합하는 것도 고려
- 멀티 노드 환경에서 Redis 분산 락 사용해서 데이터 정합성 보장
- 성능 개선의 핵심 과정은 문제 탐지 → 해결 적용 → 모니터링 반복
'빅테크 글 읽기' 카테고리의 다른 글
| [Toss Tech] 보상 트랜잭션으로 분산 환경에서도 안전하게 환전하기 (0) | 2025.04.23 |
|---|---|
| [Toss Tech] 캐시를 적용하기 까지의 험난한 길 (TPS 1만 안정적으로 서비스하기) (0) | 2025.04.11 |
| [Toss Tech] 토스증권 실시간 시세 적용기 (0) | 2025.04.04 |
| [Toss Tech] 토스 서비스를 구성하는 서버 기술 소개 (0) | 2025.03.27 |
| [Toss Tech] Spring JDBC 성능 문제, 네트워크 분석으로 파악하기 (0) | 2025.03.21 |



