DB에 데이터를 쓰는 것과 데이터를 조회하는 부분을
분리할 수는 없을까?
이번 글은 DB 아키텍처 중 Master-Slave 구조에 대해서 알아보겠습니다.
Master-Slave 구조가 무엇일까요?
Master-Slave 구조
Master-Slave 구조는 하나의 Master DB와 하나 이상의 Slave DB로 구성된 아키텍처입니다.
Master DB는 데이터를 저장 및 수정하는 역할, Slave DB는 Master DB의 데이터를 복제하고 읽기 전용으로 사용하는 역할입니다.
MySQL 공식문서에 Replication은 이렇게 명시되어 있습니다.
Replication enables data from one MySQL database server (known as a source) to be copied to one or more MySQL database servers (known as replicas). Replication is asynchronous by default; replicas do not need to be connected permanently to receive updates from a source. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
MySQL 복제(Replication)는 하나의 MySQL 데이터베이스 서버(소스)에서 하나 이상의 MySQL 데이터베이스 서버(레플리카)로 데이터를 복사하는 기능입니다. 복제는 기본적으로 비동기적으로 동작하며, 레플리카는 소스에 항상 연결되어 있지 않아도 됩니다. 구성 방식에 따라 모든 데이터베이스를 복제할 수도 있고, 선택한 데이터베이스만 복제할 수도 있으며, 심지어 특정 테이블만 복제할 수도 있습니다.
Master-Slave 구조는 왜 필요할까요?
Master-Slave가 필요한 이유
요즘 제공되는 서비스들은 점점 규모가 커질수록 대용량 트래픽을 감당해야 합니다.
DB는 서비스의 핵심 저장소이기 때문에, 트래픽이 몰리는 경우 가장 먼저 병목이 발생하는 구간입니다.
단일 DB를 사용하여 대규모 트래픽을 처리하는 경우 아래와 같은 문제가 발생합니다.
- 성능 문제 : 읽기/쓰기 요청이 한 DB에 몰리기 때문에 응답 속도가 급격하게 느려집니다.
- 가용성 문제 : DB 하나가 다운되는 경우 서비스 전체가 마비됩니다.
- 백업 문제 : 서비스 운영 중 장애가 발생한 경우, 실시간 백업에 어려움이 있습니다.
요즘 대부분의 서비스는 쓰기 및 수정 요청 보다 읽기 요청이 압도적으로 많기 때문에, Master-Slave 구조를 사용해서 읽기 요청과 쓰기 및 수정 요청을 분산해주면 성능을 개선할 수 있습니다.
Master-Slave구조를 사용하지 않고 캐싱해서 사용하면 되는거 아닌가요?
캐시는 성능을 높이는 데 유용하지만, 과도한 캐시 의존은 데이터 정합성에 치명적일 수 있습니다.
예를 들어, 사용자 잔액 같은 중요한 데이터는 반드시 최신 상태가 보장되어야 합니다. 하지만 캐싱된 값이 DB와 다를 경우, 서비스 신뢰성에 큰 타격을 줄 수 있습니다. 따라서, 돈과 관련된 데이터는 캐싱보다는 항상 실시간 조회가 원칙이 되어야 합니다.
Master-Slave구조는 어떤 흐름을 가질까요?
Master-Slave 동작 흐름
그림으로 큰 구조를 그리면 다음과 같습니다.
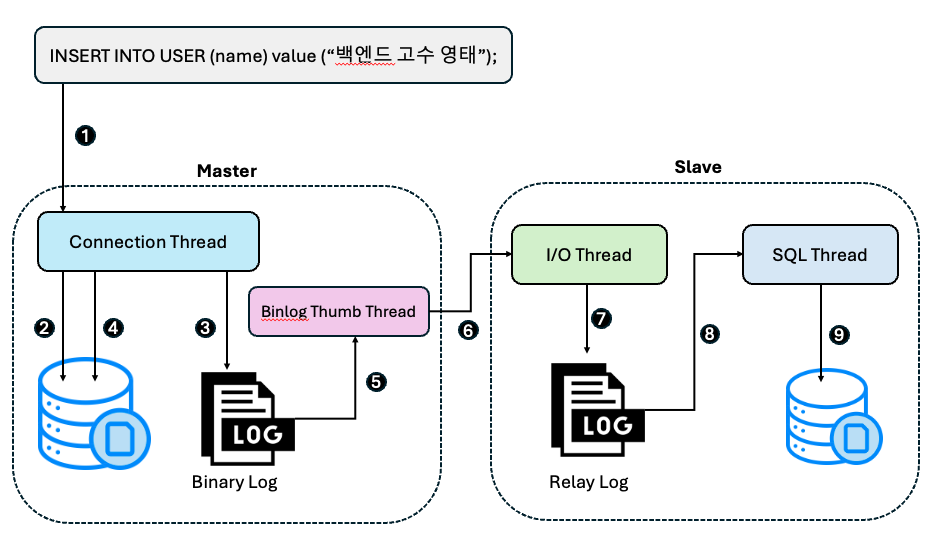
- 클라이언트에서 insert 쿼리의 트랜잭션을 Commit 합니다.
- Master Connection Thread는 Storage Engine에 해당 Transaction에 대해 Commit할 준비를 합니다.
- Commit을 하기 전에 Binary Log에 변경 사항을 기록합니다.
- Master Storage Engine에 Transaction Commit을 수행합니다.
- Master Binlog Dumb Thread에서 Binary Log를 읽습니다.
- Master Binlog Dumb Thread에서 읽은 Binary Log event를 Slave로 비동기적으로 전송합니다.
- Slave I/O Thread는 Master에서 보낸 Binary Log event를 Slave Relay Log에 기록합니다.
- Slave SQL Thread가 Relay Log를 읽습니다.
- Slave SQL Thread가 읽은 데이터를 Slave Storage Engine에 적용합니다.
Master-Slave 구조의 한계는 없을까요?
Master-Slave 구조의 장점과 한계
Master-Slave 구조에서 장점은 다음과 같습니다.
- 성능 개선 : 읽기 요청을 Slave가 처리하게 되면서, Master는 쓰기에만 집중할 수 있어서 성능이 개선됩니다.
- 읽기 부하 분산 : Slave를 여러 대 두는 경우, 트래픽이 증가에도 읽기 부하를 여러 Slave 나눠 처리할 수 있어 확장성이 좋습니다.
- 백업 용이 : Master가 장애가 나도, Slave에 동일한 데이터가 있으므로 빠르게 복구가 가능합니다.
- 가용성 개선 : Master 장애 시, Slave를 승격해서 Master로 전환하는 구조로 서비스 다운타임을 최소화할 수 있습니다.
Master-Slave 구조에서 한계점은 다음과 같습니다.
- Replication Delay : Master에서 데이터가 변경된 후, 변경된 내용이 Slave에 반영되기까지 시간이 걸리게 됩니다. 이 지연되는 시간이 길어지는 경우, 최신 데이터가 Slave에서 조회되지 않는 문제가 발생할 수 있습니다.
- 장애 복구 프로세스 필요 : Master 장애 시, Slave를 Master로 승격하는 과정이 필요합니다. 이 과정에서 제대로 관리되지 않는 경우 데이터 손실이나 데이터 불일치가 발생할 수 있습니다.
- 트랜잭션 일관성 부족 : Master와 Slave가 각각 독립적인 트랜잭션 로그를 가지기 때문에, 글로벌 트랜잭션과 같은 강한 일관성 보장이 어렵습니다.
- 쓰기 부하 분산 불가 : 쓰기 요청은 Master에서만 처리해야 하기 때문에, 쓰기 부하가 폭증하는 경우엔 Master 단일점 병목이 될 수 있습니다.
정리
- Master-Slave 구조는 하나의 Master DB와 하나 이상의 Slave DB로 구성된 아키텍처입니다.
- Master DB는 데이터를 저장 및 수정하는 역할, Slave DB는 Master DB의 데이터를 복제하고 읽기 전용으로 사용하는 역할을 합니다.
- 읽기 성능을 극대화하는 대신, 데이터 정합성과 장애 복구 프로세스를 스스로 챙겨야 하는 구조입니다.
참고 문헌
MySQL 공식문서 : https://dev.mysql.com/doc/refman/8.4/en/replication.html
'Mysql' 카테고리의 다른 글
| Index (0) | 2025.04.23 |
|---|---|
| 디스크 I/O 병목 (0) | 2025.04.22 |
| MySQL 구조와 동작 원리 (0) | 2025.02.18 |
| 커버링 인덱스 & 성능 테스트 (0) | 2025.01.30 |
| Index와 Query문 조건의 관계 (0) | 2025.01.28 |


