이번 글은 "JVM 밑바닥까지 파헤치기" 책의 2.3 핫스팟 가상 머신에서의 객체 돌아보기에 대한 부분을 정리 및 요약한 글입니다.
객체 생성
자바는 객체 지향 프로그래밍 언어로 자바 프로그램이 동작하는 동안 언제든 수시로 객체가 만들어집니다.
언어 수준 객체 생성
자바는 객체 지향 언어 프로그래밍으로 동작하는 동안 언제나 수시로 객체가 만들어집니다.
언어 수준에서는 객체 생성은 간단하게 new 키워드를 사용하면 끝납니다.
가상 머신 수준에서는 어떤 과정을 거쳐 객체가 생성될까요?
가상 머신 수준 객체 생성
가상 머신에서는 new 명령어의 바이트코드를 만나게 되면, 해당 명령의 매개 변수가 상수 풀 안의 클래스를 가리키는 심벌 참조인지 먼저 확인합니다. 그다음으로 이 참조가 뜻하는 클래스가 로딩, 해석, 초기화 되었는지 확인합니다.
만약, 준비되지 않은 클래스인 경우엔 클래스 로딩부터 해야 합니다. 로딩이 완료된 경우, 객체를 담을 메모리를 할당합니다.
왜 상수 풀 안의 클래스를 가리키는 심벌 참조인지 확인할까?
객체 생성을 위해서는 해당 클래스의 구조와 메타 정보가 메모리에 올라와 있어야 하기 때문입니다.
상수 풀에는 단지 클래스 이름 문자열열만 있는 심벌 참조 일 수 있으므로, JVM은 이를 먼저 확인하고, 필요하면 로딩/해석을 통해 직접 참조로 바꿔주는 과정이 필요하게 됩니다.
비유

객체 메모리 할당 방식
클래스가 로딩되면, 해당 클래스 인스턴스가 필요한 정확한 메모리의 크기를 계산할 수 있습니다. 이 계산은 객체가 가지는 인스턴스 변수의 총합 등을 기반으로 하게 됩니다.
JVM은 이 크기만큼 힙 메모리에서 공간을 확보해야 하는데, 힙의 구조에 따라 다음 두가지 방식 중 하나를 사용합니다.
1. 포인터 밀기(Bump-the-Pointer) 방식

힙은 일반적으로 사용 중인 메모리와 여유 메모리로 구분되어 있으며, 하나의 포인터가 이 경계를 가리키는 구조로 관리될 수 있습니다.
이때 새로운 객체를 생성하면, 필요한 메모리 크기만큼 포인터를 앞으로 이동시켜 메모리를 할당합니다. 이와 같이 단순히 포인터만 이동해 메모리를 할당하는 방식을 포인터 밀기(Bump-the-Pointer)라고 합니다.
이 방식은 메모리 할당 속도가 매우 빠르다는 장점이 있지만, 한 가지 전제가 필요합니다. 바로 힙 메모리가 조각나지 않고 연속적으로 정렬된 상태여야 한다는 점입니다. 즉, 힙의 사용 중인 영역이 한쪽에 몰려 있고, 나머지가 전부 연속된 여유 공간일 때에만 이 방식이 유효합니다.
실제로 이런 조건은 Young Generation에서 Minor GC 직후처럼, Garbage Collector가 객체를 정리한 뒤 자주 등장합니다. 이런 경우에는 객체들이 한쪽으로 몰려 있고, 포인터만 앞으로 밀면 새로운 메모리를 바로 확보할 수 있기 때문에 할당 속도 또한 매우 빠릅니다.
포인터 밀기(Bump-the-Pointer) 방식의 한계
포인터 밀기 방식은 자바 힙이 완벽하게 규칙적으로 관리되는 경우에만 적용할 수 있습니다.
요즘 사용되는 JVM에서는 가비지 컬렉션 이후에도 메모리 단편화가 발생합니다. 즉, 사용 중인 영역과 여유 메모리가 뒤섞인 구조로 존재하는 경우가 많습니다.
2. Free List 방식
포인터 밀기 방식의 한계를 극복하기 위한 방법입니다.
Free List 방식은 JVM의 메모리 블록들을 따로 리스트로 관리하면서, 객체 인스턴스를 담기에 충분한 크기의 공간을 여유 블록 목록에서 탐색해서 할당합니다.
GC는 이 두가지 방식 중 어떤 방식을 사용할까요?
GC 전략에 따라 달라지는 힙 공간 확보 방식
Compact를 수행할 수 있는 Serial, ParNew같은 GC는 힙을 모아서 연속된 공간으로 만들기 때문에, 포인터 밀기 방식이 가능해지고, 그만큼 메모리 할당 속도도 빨라집니다.
반면, Compact를 수행하지 않고 Sweep(내부 단편화)만 수행하는 CMS(Concurrent Mark and Sweep)같은 GC를 사용하는 경우에는 힙에 단편화된 여유 공간이 남기 때문에, 포인터 밀기 방식을 사용하기 어렵고, Free List 방식으로 객체가 들어갈 수 있는 공간을 탐색해서 할당합니다.
멀티스레드 환경에서의 메모리 할당 문제
포인터 밀기 방식과 Free List 방식은 단일 스레드 환경에서는 비교적 단순하게 작동합니다.
하지만, 실제 애플리케이션은 멀티스레드 환경에서 동작하기 때문에, 객체 생성이 동시에 여러 스레드에서 일어날 경우, 여유 메모리의 시작 지점을 공유하면서 충돌이 발생할 수 있습니다.
예시로, 스레드 A가 객체를 할당하려는 순간, 스레드 B도 거의 동시에 메모리를 요청하게 되면 포인터를 밀어 올리는 시점에 경쟁 조건이 생기게 됩니다.
동기화 비용과 성능 저하
앞서 나온 문제를 해결하기 위해선, 각 스레드가 메모리를 할당하는 과정에서 동기화 작업을 거쳐야 합니다.
JVM은 이 동기화를 비교 및 교환같은 방식으로 수행하지만, 매번 동기화를 거치면 성능 저하가 발생할 수 밖에 없습니다.
동기화 작업이란?
여러 스레드가 동시에 어떤 공유 자원을 접근하거나 수정하려고 할 때, 서로 충돌하지 않도록 처리 순서를 정해주는 작업
스레드 로컬 할당 버퍼(TLAB: Thread-Local Allocation Buffer)

그래서 JVM은 보다 효율적인 방법으로 각 스레드에게 미리 작은 크기의 메모리 버퍼를 따로 할당해 놓습니다. 이를 TLAB라고 합니다.
각 스레드는 이 로컬 버퍼를 이용해 객체를 생성하고, 버퍼가 가득 찼을 때만 동기화를 거쳐 새로운 버퍼를 요청하게 됩니다.
즉, 동기화 없이 객체를 빠르게 생성할 수 있는 구조를 제공하게 됩니다.
쉽게 말해, 원래 객체를 만들 때 자바는 힙 메모리에 공간을 만들어줘야 합니다. 그런데 이 힙 메모리는 모든 스레드가 같이 쓰는 공간이기 때문에, 매번 동기화를 해줘야 하고, 이는 성능을 느리게 만듭니다. 그렇기 때문에 아예 스레드마다 자기만 쓰는 작은 메모리 구역을 주어서 동기화 없이 마음껏 객체를 생성할 수 있게 해주는 것입니다. 만약, 버퍼가 다 차는 경우엔 공용 힙에서 메모리를 다시 받아 옵니다.
초기화
메모리만 할당되었다고 해서 바로 객체가 완성되는 것은 아닙니다.
JVM은 메모리를 할당한 직후, 해당 공간을 0으로 초기화 합니다. 이 덕분에 자바에서는 별도로 초기화를 하지않아도, 각 필드는 기본값(숫자면 0, 참조면 null)으로 안전하게 채워진 상태가 됩니다.
특히 TLAB을 사용하는 경우, 이 초기화 작업은 할당과 동시에 스레드 버퍼 내부에서 미리 수행되므로 더욱 빠릅니다.
자바에서는 객체의 인스턴스 필드(멤버 변수)들이 명시적으로 값을 지정하지 않아도, 자동으로 기본값을 가지게 되는데, 이는 초기화 과정 때문입니다.
메타정보 설정
그 다음으로, JVM은 객체에 대해 필요한 설정값을 부여합니다.
예시로, 해당 객체가 어떤 클래스의 인스턴스인지, GC세대 나이 정보가 어떻게 되는지, hashCode가 계산이 되었는지 등
객체가 JVM 안에서 유효하게 작동하기 위해 필요한 다양한 메타데이터들이 이 단계에서 설정됩니다. 또한, 이 정보들은 객체의 헤더에 담기게 됩니다.
JVM 관점 vs 프로그램 관점
해당 단계가 끝나면, JVM 관점에서는 객체가 만들어진 상태처럼 보이게됩니다.
중요한 건, 이 시점까지는 객체가 아직 코드에 의해 초기화되지 않았다는 것입니다. 즉, 생성자 코드인 <init>() 메서드는 아직 실행되지 않았고, 모든 필드는 단지 JVM이 초기화한 기본값만 가지고 있는 상태입니다.
자바 프로그램 입장에서 진짜 객체가 되는 시점은 생성자가 실행된 이후입니다. 생성자를 통해 필드들이 의미 있는 값으로 설정되고, 객체가 본격적으로 사용 가능한 상태로 전환되기 때문입니다.
new 명령어와 생성자의 관계
실제로 자바 코드를 컴파일하면, new 키워드는 다음과 같이 두 개의 바이트코드 명령어로 번역됩니다.

예를 들어, new 클래스명()이라고 작성을 하게 되면, 먼저 JVM이 메모리를 할당하고 초기화하는 new 바이트코드가 실행되고, 그 다음으로 invokespecial 바이트 코드를 통해 생성자가 실행되면서 개발자가 의도한 값으로 객체가 완성되게 됩니다.
바이트 코드 수준에서 보는 객체 생성
앞서 살펴본 것처럼 자바 코드를 컴파일하면 new 키워드는 JVM 바이트코드로 바뀌고, 이 바이트코드는 JVM 내부에서 객체 생성 로직을 직접 실행합니다.
HotSpot JVM의 바이트코드 인터프리터가 이 바이트코드를 해석하며 어떤 방식으로 동작하는지를 살펴보겠습니다.
단, 실제 OpenJDK에서 사용하는 기본 인터프리터는 템플릿 인터프리터입니다. 이 방식은 다양한 최적화가 적용되어 있어 성능 면에서는 유리하지만, 내부 동작을 이해하려고 하면 오히려 복잡해집니다.
바이트 코드
이 코드는 JVM 내부에서 new 명령어가 실행될 때 어떠한 과정을 거치는지 자세히 보여주는 예시입니다.
- 빠른 경로 방식 : 조건이 충족되면 TLAB에 즉시 객체를 할당하고 헤더 설정까지 마무리합니다.
- 느린 경로 방식 : 클래스가 초기화되지 않았거나, TLAB 공간 부족 등의 경우, VM 콜을 통해 객체를 생성합니다.
CASE(_new): {
u2 index = Bytes::get_Java_u2(pc + 1);
// === 빠른 경로: TLAB에 할당 시도 ===
// 조건:
// 1. 클래스 초기화 완료
// 2. 빠른 경로 할당이 가능한 클래스 (ex. finalizer 없음)
// 3. TLAB 사용 가능
ConstantPool* constants = istate->method()->constants();
if (UseTLAB && !constants->tag_at(index).is_unresolved_klass()) {
Klass* entry = constants->resolved_klass_at(index);
InstanceKlass* ik = InstanceKlass::cast(entry);
// 클래스 초기화 완료 && 빠른 경로 할당 가능 여부 확인
if (ik->is_initialized() && ik->can_be_fastpath_allocated()) {
size_t obj_size = ik->size_helper(); // 객체 크기 계산
HeapWord* result = THREAD->tlab().allocate(obj_size); // TLAB 할당 시도
if (result != NULL) { // TLAB 할당 성공
// === 초기화 ===
// (TLAB은 이미 확보된 영역이므로 간단히 0으로 초기화)
if (DEBUG_ONLY(true || !ZeroTLAB)) {
size_t hdr_size = oopDesc::header_size();
Copy::fill_to_words(result + hdr_size, obj_size - hdr_size, 0);
}
// === 객체 헤더 설정 ===
oop obj = cast_to_oop(result);
obj->set_mark(markWord::prototype()); // 마크 워드
obj->set_klass_gap(0); // 클래스 간격
obj->set_klass(ik); // 클래스 정보
OrderAccess::storestore(); // 메모리 배리어
SET_STACK_OBJECT(obj, 0); // 스택에 객체 참조 push
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1); // 다음 명령어로
break;
}
}
}
// === 느린 경로: VM 호출로 객체 생성 ===
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index),
handle_exception);
OrderAccess::storestore();
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
객체의 메모리 레이아웃
JVM에서 객체가 생성되면, 단순히 힙의 어느 공간을 차지하는 것 이상의 일이 벌어집니다. 객체는 메모리 내에서 구조적으로 3부분으로 나뉘어 저장됩니다.
- 객체 헤더
- 인스턴스 데이터
- 정렬 패딩

객체 헤더
객체의 가장 앞부분에는 헤더가 위치합니다. 이 객체 헤더는 JVM 입장에서 아주 중요한 역할을 수행하는데, 크게 3가지 정보를 담고 있습니다.
1. 마크 워드
해시 코드, GC 세대 나이, 락 관련 정보(락을 잡았는지, 어떤 스레드가 잡았는지 등), 모니터 진입 여부, 타임스탬프 등이 있습니다.
해당 정보들은 객체가 GC, 동기화, 또는 기타 JVM 내부 기능에 참여할 수 있도록 해주는 런타임 메타데이터입니다.
크기는 32비트 가상 머신에서는 32비트이고, 64비트 가상 머신에서는 64비트입니다.
32비트 핫스팟 가상 머신이고 객체가 잠겨있지 않은 경우라면, 32비트 중 25비트는 객체의 해시 코드를 저장하고, 4비트는 객체의 세대 나이를 저장하고, 1비트는 0으로 고정되며, 마지막 2비트는 락 플래그를 저장하는 데 사용됩니다.
락 플래그는 경량 락, 중량 락, GC 마크, 편향 가능 등의 정보를 표현합니다.
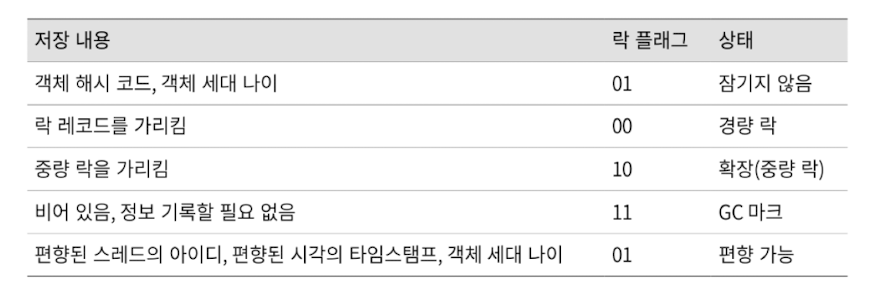
객체는 많은 런타임 데이터를 필요로 하기 때문에, 32비트나 64비트 구조에 다 담을 수 없습니다.
더욱이 객체 헤더에는 객체 자체가 정의한 데이터와 관련 없는 정보까지 담아야 해서 한정된 메모리를 최대한 효율적으로 써야 합니다.
그래서 마크 워드의 데이터 구조는 동적으로 달라집니다. 예를 들어, 락이 걸리게 되면 락 관련 정보로 바뀌고, 해시코드가 계산되면 해시코드로 바뀝니다.
2. 클래스 워드
객체가 어떤 클래스의 인스턴스인지 알기 위해, 해당 클래스의 메터데이터를 가리키는 포인터가 저장됩니다.
자바 가상 머신은 이 포인터를 통해 특정 객체가 어느 클래스의 인스턴스인지 런타임 시점에 알 수 있게 됩니다. 단, 모든 가상 머신 구현이 클래스 포인터를 객체 헤더에 저장하지는 않습니다. 다시 말해, 객체의 메타데이터 정보를 반드시 객체 자체에서 찾아야 하는 것은 아닙니다.
3. 배열 길이
배열 객체의 경우, 객체 헤더에는 배열의 길이(요소 개수) 정보가 함께 저장됩니다.
이 값은 JVM이 해당 배열 객체가 차지하는 전체 메모리 크기를 계산할 때 반드시 필요한 정보입니다.
또한 객체 헤더에는 배열에 담긴 원소의 타입을 가리키는 정보도 포함되어 있는데, 이 정보를 통해 JVM은 각 요소가 몇 바이트인지를 알 수 있습니다. 배열 객체의 크기를 정확하게 계산할때, 원소의 타입과 배열 길이라는 두 가지 정보를 모두 사용합니다.
인스턴스 데이터
객체 헤더 다음에는 인스턴스 데이터 영역이 있습니다.
이 부분은 객체가 실제로 가지고 있는 필드(멤버 변수)들의 값을 저장하는 공간입니다.
예시로, 클래스에 정의된 int age, String name과 같은 변수나 부모 클래스에서 상속받은 필드들도 모두 이 영역에 저장됩니다.
핫스팟 JVM은 기본적으로 다음과 같은 순서로 필드를 배치합니다.
long > double > int > short > char > byte > boolean
왜 이러한 순서로 배치를 할까요?
long과 double은 각각 8바이트를 차지합니다. JVM에서 객체는 8바이트 단위로 정렬(alignment) 되어야 합니다. 만약 작은 타입들을 먼저 배치하면, 나중에 long이나 double이 오면서 정렬 기준을 맞추기 위해 중간에 패딩(padding) 을 넣어야 해요. 이는 메모리 낭비를 일으킵니다.
class Example1 {
byte b; // 1바이트
long l; // 8바이트
}
[b의 크기 + 7크기의 padding][l의 크기]
[l의 크기][b의 크기 + 7크기의 padding]로 padding은 여전히 필요하지만, JVM이 이후 필드를 더 최적화 해서 해당 빈 공간을 다른 필드로 채울 수도 있습니다.
하지만 -XX:+CompactFields 옵션이 활성화되어 있으면(기본값 true) JVM은 크기가 작은 필드를 빈틈없이 끼워 넣어서 메모리를 절약합니다.
정렬 패딩
객체의 마지막 구성 요소는 정렬 패딩입니다. 말 그대로 아무런 의미가 없는 빈 공간입니다.
이 공간이 필요한 이유는 JVM이 객체를 메모리에 배치할 때 8바이트 단위(8바이트 정수배)로 정렬하기 때문입니다.
이 기준을 만족하지 않으면, 객체 뒤에 남는 부분을 패딩으로 채워 정확히 8의 배수 크기를 맞추는 것입니다.
쉽게 말해, 객체의 크기를 딱 맞춰 떨어지게 만들기 위한 메모리 정렬 장치 입니다.
객체가 어떻게 메모리에 배치되는지에 대해 전반적인 구조를 살펴봤습니다.
다음은 이렇게 배치된 객체에 JVM이 실제로 어떻게 접근하고 사용하는지에 대해 알아보겠습니다.
객체에 접근하기
자바는 객체 지향 언어이기 때문에, 대부분의 객체는 다른 객체를 참조하거나 조합해 만들어집니다.
그런데 여기서 궁금해질 수 있는 점은 JVM은 도대체 객체에 어떻게 접근할까? 입니다.
개발을 할때는 일반적으로 자바 코드에서 단순히 객체의 주소를 참조 변수에 담아 사용하지만,
JVM 내부적으로는 객체에 접근하는 방식이 구현에 따라 다르게 구성 됩니다.
자바 명세에서는 "참조는 객체를 가리키는 값이다."라고만 설명하고 있을 뿐, 그 참조가 어떠한 방식으로 객체의 메모리를 찾아가는지는 명시하지 않습니다.
따라서, HotSpot과 같은 JVM 구현체에서는 다음과 같이 2가지 방식 중 하나로 객체에 접근합니다.
(1) 핸들 방식 (Handle-based)

핸들 방식은 자바 힙 안에 별도의 핸들 풀(handle pool) 을 만들어 놓고, 스택의 참조 변수는 이 핸들 풀의 핸들 주소를 저장합니다.
이 핸들에는 객체의 인스턴스 데이터 주소, 타입 정보 주소가 함께 들어 있고, 핸들을 통해서 객체에 접근합니다.
객체의 실제 위치가 변경되더라도, 핸들만 업데이트하면 되므로 참조 변수는 그대로 유지된다는 장점이 있습니다.
특히 GC 과정에서 객체가 이동할 수 있는 환경에서는 매우 유리한 방식입니다. (참조 자체에 손댈 필요가 없어진다.)
(2) 직접 포인터 방식 (Direct Pointer-based)
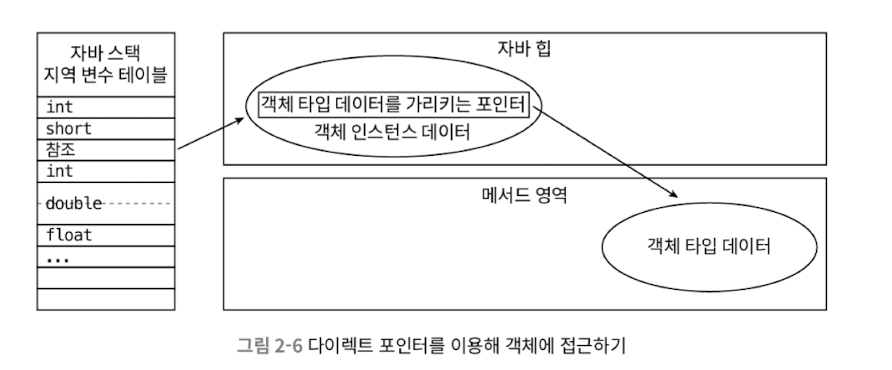
핸들 방식과 달리, 스택에 저장된 참조 변수는 객체의 실제 주소를 바로 가리킵니다. 그래서 객체의 데이터에 직접 접근할 수 있고, 속도 측면에서는 핸들 방식보다 빠릅니다.
GC가 객체를 이동시키면, 모든 참조 변수의 주소도 함께 바꿔줘야 하기 때문에 관리 비용이 크고, 성능 저하가 발생할 수 있다는 단점이 존재합니다.
핫스팟VM은 주로 다이렉트 포인터 방식을 이용합니다.
'Java' 카테고리의 다른 글
| [JVM] 저지연 가비지 컬렉터 : 세넌도어 (0) | 2025.04.21 |
|---|---|
| [JVM] OutOfMemory 예외 (0) | 2025.04.15 |
| 리플렉션(Reflection) (0) | 2025.03.07 |
| ArrayList가 크기를 늘리는 방법 (0) | 2025.02.08 |
| [Java] Serialization (2) | 2025.01.27 |



