펜윅 트리(Fenwick Tree)가 뭘까요?
펜윅트리는 가장 낮은 비트(LSB)를 기반으로 트리를 만들어 동적배열에서 구간합을 효율적으로 구할 수 있는 자료구조입니다.
또한 이진 인덱스 트리(Binary Indexed Tree, BIT)라고도 불립니다.
동적 배열이 뭘까요?
정적 배열은 배열의 요소들이 한번 선언되면, 바뀌지 않는 배열을 의미합니다.
동적 배열은 동적으로 배열의 요소들이 바뀌는 배열을 의미합니다.
정적 배열과 동적 배열의 예시는 아래와 같습니다.
정적 배열 : [10,20,30,40,50]
동적 배열 : [10,20,30,40,50] → [10,30,60,20,50]
백준에서는 아래와 같은 표현으로 동적 배열의 구간합을 구하라고 합니다.

"다섯 번째 수를 2로 바꾸고 3번째부터 5번째까지 합을 구하라" 배열의 원소들이 동적으로 변한다는걸 의미합니다.
구간합은 뭘까요?
구간합은 말그대로 구간의 합을 나타냅니다. 먼저, 정적배열에서 구간합은 아래와 같습니다.
[10,20,30,40,50]
예를들어, index가 0부터 2까지 구간의 합을 구하면 (10+20+30)으로 60이 됩니다.
index가 2부터 4까지 구간의 합을 구하면 (30+40+50)으로 120이 됩니다.
정적 배열의 구간합은 어떻게 구할 수 있을까요?
정적배열의 구간합은 누적합을 사용하면 빠르게 구할 수 있습니다.
배열로 순차 탐색을 통해 각 인덱스까지의 원소의 합을 누적시켜주는 누적합 배열을 사용합니다.
누적합 배열은 아래 이미지와 같습니다.
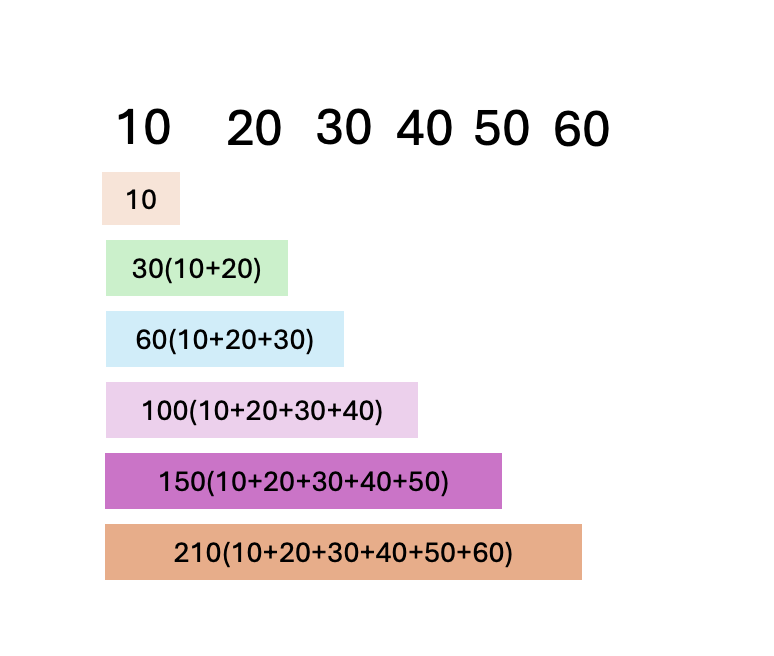
그림으로 나타낸 누적합 배열은 다음과 같습니다.
int[] arr = {10,20,30,40,50,60};
int[] pSum = {10,30,60,100,150,210};
"에..? 이걸로 구간합을 어떻게 구하죠?"
누적합 배열의 각 인덱스가 의미하는 것은 다음과 같습니다. (index는 pSum
- pSum[0] : arr[0]
- pSum[1] : arr[0] + arr[1] (0번부터 1번까지)
- pSum[2] : arr[0] + .. + arr[2] (0번부터 2번까지)
- pSum[3] : arr[0] + .. + arr[3] (0번부터 3번까지)
- pSum[4] : arr[0] + .. + arr[4] (0번부터 4번까지)
- pSum[5] : arr[0] + .. + arr[5] (0번부터 5번까지)
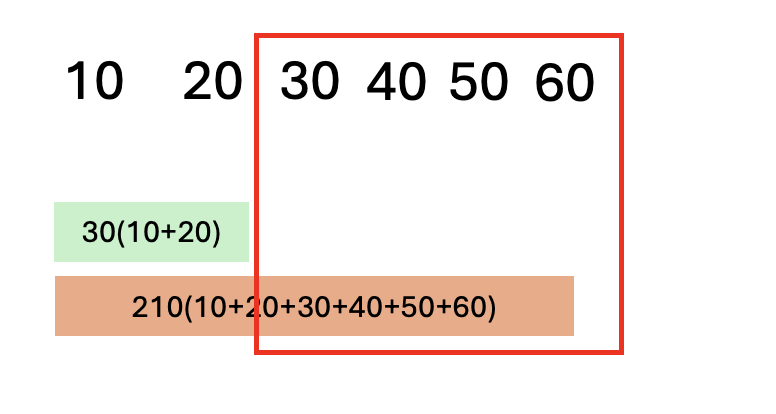
만약, 누적합 배열을 사용해서 arr배열 기준 2번 index부터 5번 index까지의 구간합을 구하려면 어떻게 해야 할까요?
pSum[5] - pSum[1] 를 해주면 됩니다. 0번부터 5번까지 더한 값에서 0번부터 1번까지 더한 값을 빼주면 2번부터 5번까지 더한 값이 됩니다.
아래 그림처럼 빼주게되면 index 2번부터 index 5번까지의 구간합은 210 - 30 = 180이 됩니다.
30 + 40 + 50 + 60을 해도 180이 나옵니다.
정적 배열은 누적합을 사용해서 구간합을 시간복잡도 O(1)로 구할 수 있습니다.
그렇다면, 동적으로 값이 변경되는 배열인 경우엔 어떻게 해야 할까요?
이를 해결하기 위해 트리 구조와 누적합 개념을 결합한 자료구조인 펜윅 트리나 세그먼트 트리를 사용하는 것입니다.
이들을 사용하면 배열 값이 변경될 때도 O(log N)으로 빠르게 구간 합을 구할 수 있습니다.
"세그먼트 트리랑 펜윅 트리의 차이점이 뭔가요?"
펜윅 트리와 세그먼트 트리는 둘 다 구간 합을 빠르게 구하고, 개별 값 업데이트를 효율적으로 수행할 수 있는 자료구조입니다.
하지만 구현 방식, 지원하는 기능, 성능 측면에서 차이가 있습니다.
대표적으로, 세그먼트 트리는 완전 이진 트리 형태로 노드를 직접 저장하는 구조인 반면, 펜윅 트리는 배열을 기반으로 하며, 비트 연산(index & -index)을 이용해 동작합니다.
즉, 펜윅 트리는 노드를 명시적으로 생성하지 않고 배열과 비트 연산을 활용해 빠르게 연산하는 방식입니다.
펜윅 트리를 트리 형태로 나타내면 아래와 같습니다.
(이해를 돕기 위해 그림으로 표현했지만, 실제로 펜윅 트리는 노드를 직접 사용하지 않고, 배열과 비트 연산을 활용해 동작합니다.)

숫자는 각 노드를 의미합니다. 총 1번 노드부터 6번 노드까지 6개의 노드가 존재합니다.
이 노드가 의미하는 것은 다음과 같습니다.
- 1번 노드 : 0번 인덱스 ~ 0번 인덱스의 구간합
- 2번 노드 : 0번 인덱스 ~ 1번 인덱스의 구간합
- 3번 노드 : 2번 인덱스 ~ 2번 인덱스의 구간합
- 4번 노드 : 0번 인덱스 ~ 3번 인덱스의 구간합
- 5번 노드 : 4번 인덱스 ~ 4번 인덱스의 구간합
- 6번 노드 : 4번 인덱스 ~ 5번 인덱스의 구간합
만약, 1번 인덱스 ~ 3번 인덱스의 구간합을 구하고자 할때는 어떻게 해야할까요?
4번 노드의 값에서 1번 노드의 값을 빼줍니다. 그림으로 나타내면 다음과 같습니다.

"각 노드에 특정 구간의 합을 저장하는건 알겠는데, 무슨 기준으로 구간을 정하는 건가요?"
펜윅 트리에서 LSB를 이용해 특정 인덱스부터 영향을 받는 모든 구간을 갱신하는 과정을 진행합니다.
즉, index & -index를 사용하여 현재 인덱스에서 다음으로 영향을 받는 인덱스를 빠르게 찾으면서 업데이트를 합니다.
모든 구간을 갱신하는 업데이트 코드는 아래와 같습니다.
public void update(int index, int value) {
while (index <= size) {
tree[index] += value;
index += index & -index;
}
}
배열의 index가 0일때 부터, index가 5일때까지 하나씩 갱신을 시켜보겠습니다.
먼저, index가 0일 때 값은 10이므로 update(1, 10)을 호출합니다.
(펜윅 트리는 비트 연산(index & -index)을 활용하기 때문에 1-based index(1부터 시작)을 사용합니다.)
update(1, 10) 수행
첫번째 depth입니다.
- index = 1, value = 10
- index & -index = 1
- tree[1] += 10 (자기 자신 갱신)
index & -index의 연산 방식은 아래와 같습니다.
1을 2진수로 표현하면 0001 입니다.
-1을 2진수로 표현하면 1000으로 보수를 취한뒤 1을 더해준 1111이 됩니다.
0001 & 1111 = 0001이 됩니다.
두번째 depth입니다.
- index = 1 + 1 = 2
- tree[2] += 10
- index & -index = 2
- index = 2 + 2 = 4
세번째 depth입니다.
- tree[4] += 10
- index & -index = 4
- index = 4 + 4 = 8 (범위 초과, while문 break)
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 | 0 | 10 | 0 | 0 |
update(2, 20) 수행
첫번째 depth
- index = 2, value = 20
- index & -index = 2
- tree[2] += 20
두번째 depth
- index = 2 + 2 = 4
- tree[4] += 20
- index & -index = 4
- index = 4 + 4 = 8 (범위 초과, 종료)
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 0 | 10 + 20 | 0 | 0 |
update(3, 30) 수행
첫번째 depth
- index = 3, value = 30
- index & -index = 1
- tree[3] += 30
두번째 depth
- index = 3 + 1 = 4
- tree[4] += 30
- index & -index = 4
- index = 4 + 4 = 8
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10 + 20 + 30 | 0 | 0 |
update(4, 40) 수행
첫번째 depth
- index = 4, value = 40
- index & -index = 4
- tree[4] += 40
두번째 depth
- index = 4 + 4 = 8 (범위 초과, 종료)
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10+20+30+40 | 0 | 0 |
update(5, 50) 수행
첫번째 depth
- index = 5, value = 50
- index & -index = 1
- tree[5] += 50
두번째 depth
- index = 5 + 1 = 6
- tree[6] += 50
- index & -index = 2
- index = 6 + 2 = 8 (범위 초과, 종료)
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10+20+30+40 | 50 | 50 |
update(6, 60) 수행
첫번째 depth
- index = 6, value = 60
- index & -index = 2
- tree[6] += 60
두번째 depth
- index = 6 + 2 = 8 (범위 초과, 종료)
표로 정리하면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10+20+30+40 | 50 | 50 + 60 |
이전에 봤던 그림이랑 표가 일치하게 됩니다.
그렇다면, 펜윅 트리는 어떻게 동적 배열의 구간합을 빠르게 구할 수 있는 걸까요?
동적 배열은 값이 변하는 배열입니다. 만약, 값이 변하게 되는 경우 이 값이 속한 구간합의 값을 전부 수정해야 합니다.
예를 들어, 배열에서 마지막 원소의 값이 60에서 70으로 변경되었다고 가정하면, tree의 배열에서 6번 인덱스의 값은 50+70이 되어야 합니다. 표로 나타내면 다음과 같습니다.
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10+20+30+40 | 50 | 50 + 60 |
| index | 1 | 2 | 3 | 4 | 5 | 6 |
| tree | 10 | 10 + 20 | 30 | 10+20+30+40 | 50 | 50 + 70 |
값이 매번 변할 때마다 완전 탐색을 통해 변경할 위치를 찾으면 시간 복잡도가 너무 높아집니다.
펜윅 트리는 이 문제를 해결하기 위해 비트 연산(index & -index)을 이용하여 O(log N) 시간 복잡도로 변경할 위치를 빠르게 찾습니다.
배열의 마지막 원소 60이 70으로 변경되는 경우엔 아래와 같이 udpate 함수를 호출해 줍니다.
update(6, 70 - 60 = 10) 수행
값이 60 → 70으로 변경되므로, 차이값 70 - 60 = 10을 적용해 줍니다.
- tree[6] += 10
- index + (index & -index) = 6 + 2 = 8 (범위 초과, 종료)
펜윅트리를 코드로 구현하면 어떻게 될까요?
구현 코드
public class FenwickTree {
private static int[] tree;
private static int size;
public static void update(int index, int value) {
while (index <= size) {
tree[index] += value;
index += index & -index;
}
}
public static int sum(int index) {
int result = 0;
while (index > 0) {
result += tree[index];
index -= index & -index;
}
return result;
}
public static int rangeQuery(int left, int right) {
return sum(right) - sum(left - 1);
}
public static void main(String[] args) {
int[] data = {3, 4, 10, 11};
int n = data.length;
tree = new int[n + 1];
size = n;
for (int i = 0; i < n; i++) {
update(i + 1, data[i]);
}
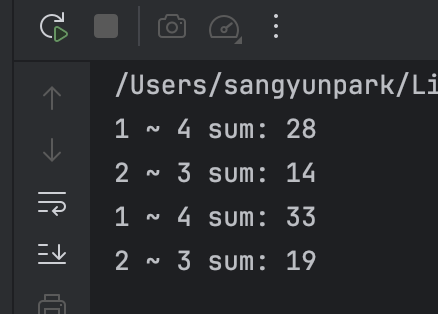
System.out.println("1 ~ 4 sum: " + rangeQuery(1, 4));
System.out.println("2 ~ 3 sum: " +rangeQuery(2, 3));
update(2, 5);
System.out.println("1 ~ 4 sum: " + rangeQuery(1, 4));
System.out.println("2 ~ 3 sum: " + rangeQuery(2, 3));
}
}
출력 결과
"sum 메서드는 왜 사용해주나요?"
펜윅 트리(Fenwick Tree)는 일반적인 누적합(Prefix Sum) 배열과 다르게 값을 저장하기 때문에,
단순히 tree[index]를 참조하는 것만으로는 원하는 구간의 합을 알 수 없습니다. 그래서 sum(index)가 필요한 값만 빠르게 찾아 더하는 역할이 필요합니다.
int[] arr = {10,20,30,40,50,60};
int[] pSum = {10,30,60,100,150,210}; // 일반 누적합
int[] tree = {10,30,30,100,50,120}; // 펜윅 트리
펜윅 트리는 일반적인 누적합 배열과 다르게 값을 저장하기 때문에, 단순히 tree[index]를 참조하는 것만으로는 원하는 구간의 합을 알 수 없습니다. 그래서 sum(index) 함수가 필요한 값들만 빠르게 찾아 더하는 역할이 필요합니다.
예를 들어, arr 배열에서 0번 ~ 2번 인덱스의 합을 구한다고 가정하면,
- 일반 누적합(pSum[])에서는 pSum[2]을 바로 참조하면 60이 나옵니다.
- 펜윅 트리(tree[])에서는 tree[2]를 참조하면 30이 나오지만, 이는 전체 합이 아닙니다.
- 펜윅 트리는 일부 구간의 합만 저장하기 때문에, sum(3)을 이용해야 정확한 값을 구할 수 있습니다.
정리
- 펜윅 트리는 특정 구간의 합을 빠르게 구하기 위한 자료구조입니다.
- 일반적인 누적합(Prefix Sum)보다 더 효율적으로 업데이트(update)와 조회(sum)를 수행할 수 있습니다.
- 구간 합(sum)과 값 변경(update)을 O(log N)의 시간 복잡도로 처리할 수 있습니다.
'Algorithm' 카테고리의 다른 글
| [프로그래머스] Lv3 - 최적의 행렬 곱셈 (0) | 2025.02.25 |
|---|---|
| [프로그래머스] Lv 3. 블록 이동하기 (0) | 2025.02.24 |
| 최대 증가 부분 수열 (2) | 2025.02.22 |
| [프로그래머스] Lv3 카운트 다운 (1) | 2025.02.20 |
| [프로그래머스] Lv3 선입 선출 (0) | 2025.02.19 |



