인덱스를 사용해서 쿼리 조회
성능을 개선한 경험을 글로 작성하였습니다.
준비물
Mysql에 100만개의 데이터를 먼저 넣어줍니다.
@Test
@DisplayName("대용량 데이터 넣기")
void bulkInsert() throws Exception{
//given
EasyRandom easyRandom = PostFactory.get(3L, LocalDate.of(1999,1,1), LocalDate.of(2024, 2,1));
//when
ObjectStopWatch.start();
List<Post> posts = IntStream.range(0, 10000 * 100)
.parallel()
.mapToObj(i -> easyRandom.nextObject(Post.class)).toList();
ObjectStopWatch.stop();
System.out.println("객체 생성 시간 : " + ObjectStopWatch.getTotalTimeSeconds());
QueryStopWatch.start();
postRepository.bulkInsert(posts);
QueryStopWatch.stop();
//then
System.out.println("DB 쿼리 시간 : " + QueryStopWatch.getTotalTimeSeconds());
}

100만 데이터 조회하기

select문을 사용해서 '1990-01-01'과 '2023-02-01' 사이에 존재하는 데이터를 조회합니다.
조회를 할때, cpu 사용량이 얼마나 되는지 확인하기 위해서 top을 사용해줍니다.
top : Linux 운영체제에서 실시간으로 시스템의 상태와 프로세스 정보를 모니터링할 수 있는
명령어이다. 주로 CPU, 메모리 사용량, 각 프로세스의 상태 등을 실시간으로 확인할 수 있어, 시스템의
성능 상태를 진단하는 데 유용합니다.


조회 쿼리를 날리기전 CPU 사용율은 0.1입니다.
조회 쿼리를 날릴때, 순간적으로 CPU 사용률이 84.9까지 갑자기 확 튑니다.

쿼리를 조회하는데도 1s 183ms가 걸립니다.
쿼리 동작 확인하기
explain을 사용해서 쿼리를 어떻게 실행하는지, 즉 쿼리 실행 시 어떤 인덱스를 사용하는지 또는 테이블을 어떻게 스캔하는지 등을 확인합니다.
explain 명령어 : MySQL에서 쿼리의 실행 계획을 분석할 수 있는 명령어


type : ALL
Full Table Scan을 의미합니다. 이 쿼리는 인덱스를 사용하지 않고 테이블의 모든 행을 읽고 있습니다.
Disk I/O에 있는 데이터에 다 접근했다고 볼 수 있습니다.
테이블을 전부 스캔할 필요가 있었을까요?
1990-01-01부터 2021-02-01까지 총 데이터의 갯수를 조회 해보았습니다.

조회결과
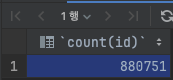
총 880,751개의 데이터가 존재하는데, 조회문을 실행하면 100만개의 데이터 전부 접근해서 조건에 맞는 데이터를 찾고 있습니다.
약 22만개 정도 불필요한 데이터를 스캔하고 있었습니다.
인덱싱으로 성능 최적화하기
먼저, 인덱스를 생성해줍니다.

user_id, created_date 단일 인덱싱과 user_id와 created_date의 복합 인덱싱을 해줍니다.
1. user_id 인덱스를 사용한 경우


인덱싱을 했음에도 불구하고 기존에 1s 183ms 에서 2s 265ms로 시간이 더 걸렸습니다.
왜그럴까? user_id로는 인덱싱의 효과를 볼 수 없다. user_id는 종류가 한종류(user_id가 3인경우) 밖에 존재하지 않습니다.
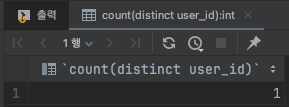
즉, user_id의 낮은 선택성으로 인해서 성능개선이 되지 않는 것입니다.
또한, 기존에는 조회시 테이블만 스캔해서 확인했지만, 인덱싱을 하게 되면 인덱스 테이블과 데이터가 존재하는 테이블을 둘 다 조회하므로 시간이 더 걸릴 수 밖에 없습니다.
이러한 경우에는 인덱스를 사용하지 않고, 테이블을 Full Scan하는 것이 더 빠를 수 있습니다.
그럼 좀 더 선택성이 높은 created_date를 인덱스를 사용해서 조회 해보겠습니다.
2. created_date 인덱스를 사용한 경우


기존에 1s 183ms 에서 200ms로 조회 시간이 약 5배 정도 줄어들었습니다.
created_date의 선택성은 다음과 같습니다.

created_date를 기준으로 했을때, 9162개의 다른 선택이 존재합니다.
3. user_id, created_date 인덱스를 사용한 경우


109ms로 조회 시간이 약 10배 정도 줄어들었다.
두가지 조건을 동시에 처리하게 되서 두개의 컬럼을 조회하는 상황에선 굉장히 빠르고 효율적입니다.
group by user_id, created_date로 데이터를 그룹화할 때도 복합 인덱스가 이미 데이터가 정렬되어 있기 때문에 추가적인 정렬 비용이 거의 필요가 없게 됩니다.
결론
같은 인덱스라도 데이터 분포, 어떠한 컬럼이 사용되는지, group by는 어떻게 되는지 잘 고려해야 더 극한의 성능을 사용할 수 있습니다.
인덱스는 양날의 검과 같습니다. 잘 활용하지 않으면, 안하는게 더 빠를 수 있습니다. 인덱스를 잘 설계하는게 중요하다고 생각합니다.
'성능 개선' 카테고리의 다른 글
| Fan Out TimeLine on Read vs Write (4) | 2024.10.11 |
|---|---|
| Cursor기반 페이지네이션으로 응답 속도 개선하기 (5) | 2024.10.10 |
| [테스트 환경] 벌크 쿼리(Bulk Query) 사용하기 (0) | 2024.10.07 |


